1.什么是前端工程化
前端工程化是指通过工具和流程的优化,使前端开发更加高效和可维护。它可以涉及到各种不同的方面,包括代码管理、脚手架工具、包管理工具、构建工具、自动化测试、代码质量检查、性能优化等等。前端工程化通常包括以下几个方面:
- 代码管理:使用版本控制工具如 Git 或 SVN 等,协作开发和管理代码库,实现代码的版本控制、代码合并、代码回退等功能。
- 脚手架工具:前端脚手架是一个用于快速搭建前端项目的工具,它可以提供项目的基础结构、文件组织方式、开发规范等。脚手架通常集成了多个工具和框架,如 Webpack、Babel、ESLint 等,使用 Vue-cli、React Create App、Angular CLI 等脚手架可以降低搭建项目的门槛,提供标准化的项目结构和规范,有利于提升项目可维护性和稳定性。除此之外,脚手架可以快速进行项目初始化、构建、打包、测试、部署等操作。
- 包管理工具:使用 pnpm、yarn、npm 实现依赖安装、版本管理、依赖更新等操作。
- 构建工具:使用构建工具如 Vite、Webpack、Rollup 等,将多个代码文件打包成一个或多个可执行的文件,同时进行资源优化、压缩等操作,以提高页面加载速度和性能。
- 自动化测试:使用自动化测试工具如 Vitest、Jest、Mocha 等,实现自动化测试,以确保代码的质量和可靠性。
- 代码规范:使用代码质量检查工具如 ESLint、Prettier 等,检查代码规范、代码风格等问题,以确保代码的可读性和可维护性。使用 commitLint 检查 Git Commit 提交规范、使用 changeset 管理版本及更新日志。
- 性能优化:使用性能优化工具如 Lighthouse、PageSpeed Insights 等,对页面进行性能分析和优化,以提高页面的响应速度和用户体验。
- CI/CD:通过 CI/CD 工具(Jenkins、GitLab 等等)自动化项目持续集成、持续部署效率。
- 监控与埋点:使用 Sentry 等监控工具监控应用错误信息并统计,降低排查错误难度。
通过前端工程化的实践,可以提高前端开发的效率和质量,同时也可以减少人为错误和重复工作,从而使团队更加高效和协作。
2.npm install 安装依赖的过程?
当使用 npm install 安装依赖时,npm 会执行以下几个步骤:
- 解析依赖。npm 首先会解析项目的 package.json 文,查找需要安装的依赖和版本号,以及它们的依赖关系,即 dependencies 和 devDependencies。npm 会根据依赖的类型(dependencies 还是 devDependencies)来决定是否将依赖安装到生产环境还是开发环境中。
- 下载依赖。npm 会从 npm 的官方 registry 中下载所有需要安装的依赖包,以及这些依赖包的所有依赖项。
- 安装依赖。npm 会将下载的所有依赖包安装到项目的 node_modules 目录中。如果依赖包已经存在于 node_modules 中,npm 会检查它们的版本是否满足要求。如果版本不符合要求,npm 会尝试更新依赖包的版本。
- 执行钩子。npm 会执行 preinstall、postinstall、preuninstall、postuninstall 钩子,以及 prepublish 和 prepare 钩子。
- 生成 package-lock.json。npm 会生成一个 package-lock.json 文件,用于锁定依赖包的版本号,以保证在不同的机器上安装依赖时使用相同的版本。
- 执行依赖命令。最后,npm 会执行依赖包的 bin 命令,以确保依赖包已经正确地安装并可用。
3.pnpm 对比 npm、yarn 有哪些优点?
- 节省磁盘空间并提升安装速度。
- 更严格高效。node_modules 中的文件是从一个单一的可内容寻址的存储中链接过来的,代码无法访问任意包。
- 内置支持 monorepo。pnpm 通过 workspace 天然内置支持 monorepo。
3.1 节省磁盘空间并提升安装速度
当使用 npm 或 yarn 时,如果有 100 个项目,并且所有项目都有一个相同的依赖包,那么,在硬盘上就需要保存 100 份该相同依赖包的副本。如果是使用 pnpm,依赖包将被存放在一个统一的位置,因此:
- 如果对同一依赖包需要使用不同的版本,则仅有版本之间不同的文件会被存储起来。例如,如果某个依赖包包含 100 个文件,其发布了一个新版本,并且新版本中只有一个文件有修改,则 pnpm update 只需要添加一个 新文件到存储中,而不会因为一个文件的修改而保存依赖包的 所有文件。
- 所有文件都保存在硬盘上的统一的位置。当安装软件包时,其包含的所有文件都会硬链接自此位置,而不会占用额外的硬盘空间。这可以在项目之间方便地共享相同版本的依赖包。
3.2 创建非扁平的 node_modules 目录
在 npm1 和 2 中,包是通过嵌套结构进行管理的,通过这种方式管理包,有多种缺点:
- 依赖无法被共用,例如 bar 和 bar1 两个模块引用了相同版本的 foo,嵌套结构会安装两次 foo,造成磁盘空间的浪费,以及安装依赖时的低效。
- 依赖层级太深,导致文件路径过长,在不同的操作系统下有存在问题,在 windows 中复制目录会报错,路径长度超过限制。
npm3 为了解决 npm1 和 2 的缺陷,通过对依赖进行扁平化处理,用于解决依赖无法被共用和依赖层级太深的问题,所有的依赖都被平铺在 node_modules 中的一级目录。这样在安装新的依赖时,根据 node 加载模块的路径查找算法,递归向上查找 node_modules 中的 package,这种查找核心简单来说是:
- 优先在同级目录查找 node_modules 文件夹。
- 如果同级目录下没有 node_modules 或者没有找到相关版本的依赖,会继续在上一级目录中查找,解决了包重复安装的问题,本地开发项目大小得到了改善。
随着 node_modules 扁平化的提出,可能会导致幽灵依赖和依赖分身。因为扁平化处理,把所有依赖都提升到 node_modules 的一级目录,导致在工作区未声明的包,可以直接被项目引用,这种现象被称为幽灵依赖(Ghost Dependency),幽灵依赖可能会导致以下问题:
- 项目体积增大。幽灵依赖会占用项目的空间,导致项目体积增大,增加传输和加载的时间。
- 安全漏洞。幽灵依赖可能存在安全漏洞,因为它们没有得到更新或者升级。
- 构建速度下降。由于幽灵依赖需要被下载和处理,可能会导致构建速度变慢。
以安装 express 为例:
- 项目可以直接引用 debug,但是却不能规定 debug 版本,导致项目每次执行 install 发布上线存在隐患。
- 对于本地开发在 devDependence 声明的,依赖的依赖也被提升到 node_modules 的一级目录,在项目中未声明就引入,导致线上出现问题。
web-project
| -- node_modules
| -- express
| -- debug@2.6.9
| --express-session@1.16.1(dev)因为扁平化处理会提升包所在目录层级,但是存在同一个包的不同版本,npm 会选择一个版本提升到 node_modules 一级目录,其他版本嵌套安装,这样做会导致在项目中引用 C 和 D 的时候,是使用两个 B 的实例,从而造成依赖分身。依赖分身在一些边界情况就会导致项目的崩溃(typescript 和 Webpack 都有可能因此出错,所以只能内部做兼容)。
web-project
| -- node_modules
| -- A@1.0
| -- B@1.0
| -- C@1.0
| -- node_modules
| -- B@2.0
| -- D@1.0
| -- node_modules
| -- B@2.0在 pnpm 中通过自动硬链接(hard link)和软链接(sybolic link)来实现 npm 模块的管理,从而避免幽灵依赖和依赖分身的问题。pnpm 安装管理时并不会像 npm 将所有依赖都扁平化管理,而是通过软链的形式链接到.pnpm 内部,再去详细管理依赖的版本,从而一并解决幽灵依赖和依赖分身。在.pnpm 内部也是平铺的,但是是允许不同版本的依赖平铺在一个层级,同时对于 express 诸多依赖,也是直接软链到平铺的模块中。
web-project
| -- node_modules
| -- express -> .pnpm/express@3.20.3/node_modules/express
| -- .pnpm
| -- express@3.20.3
| -- node_modules
| -- basic-auth -> ../../basic-auth@1.0.0/node_modules/basic-auth
| -- commander -> ../../commander@2.6.0/node_modules/commander3.3 内置支持 monorepo
4.常见的模块化方案有哪些?
JavaScript 模块化是指将代码组织成独立且可复用的模块,每个模块封装特定的功能。通过模块化,可以避免代码之间的相互依赖和冲突,提高代码的可维护性、可读性和可扩展性。模块化通常包括定义模块(导出模块)和使用模块(导入模块)两个方面。
在模块化之前通常使用<script>脚本的方式组织模块,这种方式需要明确<script>的加载顺序来保证模块之间的依赖关系,而且由于模块之间的作用域默认都是全局,很容易发生命名冲突的避免,复用性也很差。因此在前端发展史中出现了各种各样的模块化方案来解决模块化管理问题,常见的模块化方案包括:
- IIFE(立即调用函数表达式):IIFE 是通过创建一个函数作用域来避免全局变量污染,并且可以实现简单的模块化。
- CommonJS:CommonJS 是 Node.js 默认的模块化规范,通过 require 和 module.exports 来导入和导出模块。它是同步加载的,适用于服务器端。
- AMD(Asynchronous Module Definition,即异步模块定义):一种异步模块定义方式,主要用于浏览器端,代表库是 RequireJS。它通过 define 和 require 来定义和加载模块。
- UMD(Universal Module Definition,即通用模块定义):一种兼容多种模块化规范的方式,旨在解决跨平台模块化的问题。它可以同时支持 AMD、CommonJS 和全局变量。
- ESM(ES6 Module):ESM 模块是现代 JavaScript (es6 版本)的标准模块化方案,使用 import 和 export 关键字来导入和导出模块。它是静态分析的,能够支持高级优化。由于 ESM 是静态分析的,因此可以通过 Tree Shaking 删除无用代码。Tree Shaking 是一种通过移除 JavaScript 中未使用的代码来优化打包体积的技术。它通常依赖于 ES6 模块,因为它们的静态结构特性使得工具能够准确地分析代码的依赖关系,从而删除无用代码。
4.1 CommonJS 与 ESModule 的区别?
CommonJS 和 ESModule 是 JavaScript 中两种不同的模块系统。其区别如下:
- 语法不同。CommonJS 使用
require()和module.exports来导入和导出模块,而 ESModule 使用import和export语句。 - 加载方式不同。CommonJS 是同步加载模块,即当使用
require()加载一个模块时,会立即执行该模块的代码,并返回该模块的exports对象。而 ESModule 是异步加载模块,即在使用 import 语句加载一个模块时,不会立即执行该模块的代码,而是在需要使用该模块时再执行。 - 静态解析不同。由于 ESModule 采用静态解析,因此在编译时就可以确定导入的模块,而 CommonJS 则是动态解析,需要在运行时才能确定导入的模块。由于 ESModule 采用静态分析,因此可以在编译阶段确定哪些代码未被使用,从而实现 tree shaking(摇树)优化,去除未使用的代码。
- 变量绑定不同。ESModule 中导入的变量是只读的,不能被修改,而 CommonJS 导入的变量是可以被修改的。
- 应用场景不同。CommonJS 主要应用于服务器端的 Node.js 环境中,而 ESModule 主要应用于浏览器端的 Web 应用程序中。
需要注意的是,由于 CommonJS 和 ESModule 有不同的语法和特性,因此它们之间的模块无法直接互相引用,需要通过转换工具进行转换。例如,Babel 可以将 ESModule 转换成 CommonJS,而 Webpack 可以将 CommonJS 转换成 ESModule。
4.2 CommonJS 模块 require()的过程?
5.什么是 AST?
AST(Abstract Syntax Tree),抽象语法树,是一种数据结构,它用于表示编程语言的抽象语法结构。在编程语言中,源代码是由一系列字符组成的,计算机并不能直接理解它们,需要将其转换成抽象语法树,以便计算机能够理解和处理它们。
抽象语法树可以看作是源代码的抽象语法结构的一种中间表示形式。在抽象语法树中,每个节点表示一个语法元素,例如函数、变量、表达式、语句等等。节点之间的关系则表示语法结构的嵌套关系,例如函数包含参数和函数体,函数体又包含多个语句,语句包含多个表达式等等。抽象语法树在编译器、静态分析、代码优化、代码生成等领域中都有广泛的应用,例如 Babel(前端编译器)、Webpack(打包器)、ESLint(JS Lint 工具)、Perttier(代码格式化工具)等。
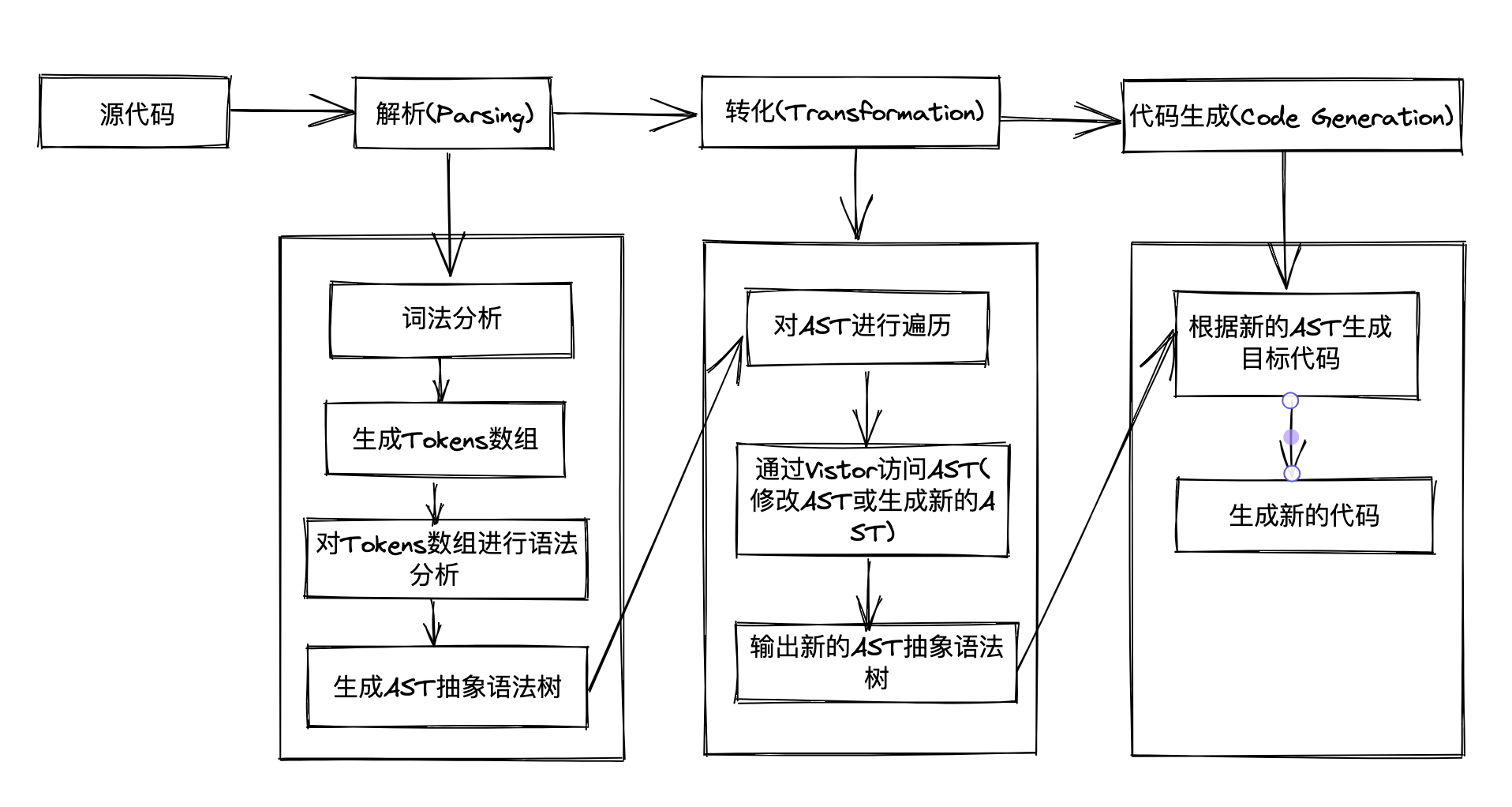
5.1 如何实现一个 Compiler?
一个完整的编译器整体执行过程可以分为三个步骤:
- Parsing(解析)。这个过程要经词法分析、语法分析、构建 AST(抽象语法树)一系列操作。
- Transformation(转化)。这个过程就是将上一步解析后的内容,按照编译器指定的规则进行处理,形成一个新的表现形式。
- Code Generation(代码生成)。将上一步处理好的内容转化为新的代码。
 以 lisp 的函数调用编译成类似 C 的函数为例:
以 lisp 的函数调用编译成类似 C 的函数为例:
LISP 代码: (add 2 (subtract 4 2))
C 代码: add(2, subtract(4, 2))
释义: 2 + ( 4 - 2)5.1.1 Parsing 过程
解析过程主要分为词法分析和语法分析两个步骤:
- 词法分析:词法分析是使用 tokenizer(分词器)或者 lexer(词法分析器),将源码拆分成 tokens,tokens 是一个放置对象的数组,其中的每一个对象都可以看做是一个单元(数字,标签,标点,操作符...)的描述信息。例如对"你是猪"进行词法分析就可以得到主谓宾词语,对
(add 2 (subtract 4 2))进行词法分析后得到:
;[
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
]- 语法解析:将词法分析的结果转化为抽象语法树(AST),并检查其语法是否正确。语法分析会将 tokens 重新整理成语法相互关联的表达形式,这种表达形式一般被称为中间层或者 AST(抽象语法树)。对
(add 2 (subtract 4 2))进行语法解析后得到的 AST:
{
type: 'Program',
body: [{
type: 'CallExpression',
name: 'add',
params:
[{
type: 'NumberLiteral',
value: '2',
},
{
type: 'CallExpression',
name: 'subtract',
params: [{
type: 'NumberLiteral',
value: '4',
}, {
type: 'NumberLiteral',
value: '2',
}]
}]
}]
}Compiler 实现
根据 Compiler 的执行流程,Compiler 的实现分为以下四个步骤:
- 生成 Tokens。
- 将生成好的 tokens 转化为 AST。
- 遍历和访问生成好的 AST。
- 将生成好的 AST 转化为新的 AST。
- 根据转化的 AST 生成目标代码。
生成 Tokens
第一步是将输入代码解析为 tokens。这个过程需要 tokenzier(分词器)函数,整体思路就是通过遍历字符串的方式,对每个字符按照一定的规则进行switch case,最终生成 tokens 数组。
6.什么是 Babel?
Babel 是一个 JavaScript 编译器,主要用于将 ECMAScript 2015+ 代码转换为当前和旧浏览器或环境中向后兼容的 JavaScript 版本,Babel 常用于语法转换(Transform syntax)、源代码转换(Source code transformations)、目标环境中缺少的 Polyfill 的场景。Babel 的执行流程分为解析、转换、生成三个步骤:
- 解析阶段:Babel 首先会将输入的源代码解析成抽象语法树(AST)。这一步骤由 Babel 的解析器完成,将源代码转换为一种更易于处理的数据结构,即 AST。
- 转换(Transformation)阶段:在解析的基础上,Babel 将对 AST 进行转换。这个阶段涉及到一系列的插件,每个插件负责一种转换。插件可以修改、添加或删除 AST 中的节点,实现对源代码的不同转换。
- 代码生成(Code Generation)阶段:转换完成后,Babel 会将修改后的 AST 转换回字符串形式的代码。这个阶段由 Babel 的代码生成器完成,它会根据修改后的 AST 生成目标版本的 JavaScript 代码。例如生成 sourcemap(源码映射)有利于开发调试。
7.什么是 Webpack?Webpack 的打包流程?
Webpack 的打包流程可以分为以下几个步骤:
- 解析配置文件:Webpack 会读取并解析配置文件(通常是 webpack.config.js 文件),并根据配置生成一个 Compiler 对象。
- 读取入口文件:Webpack 根据配置中的入口文件,读取这些文件及其依赖的模块,并将它们组成一个依赖图。
- 解析模块依赖:Webpack 会根据模块之间的依赖关系,递归地解析它们的依赖,直到所有的依赖都被解析完毕。
- 加载模块:Webpack 会根据模块的路径,使用相应的 Loader 加载模块的源代码,并将其转换为 Webpack 可以处理的形式。
- 转换代码:Webpack 会根据配置中的插件,对加载的模块进行一系列的转换操作,比如压缩、合并、优化等。
- 生成代码:Webpack 会将所有模块转换后的代码合并成一个或多个文件,并输出到指定的输出目录中。
8.Webpack Loader 和 Plugin 的区别?
Loader 和 Plugin 是 Webpack 的核心概念,两者区别如下:
- Loader:Loader 用于对模块的源代码进行转换,它直接影响到文件的加载和解析。例如,可以使用 Babel Loader 将 ES6+的代码转换为 ES5,或者使用 CSS Loader 加载和转换 CSS 文件。开发中常用的 Loader 如下:
- babel-loader:用于将新版本的 JavaScript 代码转换为旧版本的 JavaScript 代码,以确保在不同环境中运行。
- css-loader 和 style-loader: 处理 CSS 文件,使其能够被 Webpack 识别和加载到应用中。
- file-loader:处理图片、字体等文件,将它们复制到输出目录,并返回文件路径。
- url-loader:类似于 file-loader,但可以根据文件大小将文件转换为 DataURL,减少 HTTP 请求。
- sass-loader 和 less-loader:用于处理 Sass 和 Less 文件,将其编译为 CSS。
- cache-loader:用于缓存文件的转换结果,以提高构建性能。
- vue-loader:用于处理 Vue.js 的单文件组件(.vue 文件)。Vue.js 单文件组件将 HTML、CSS 和 JavaScript 封装在一个文件中,vue-loader 负责将这种文件进行解析和转换,使得它们可以被 Webpack 正确地加载和使用。
- Plugin:Plugin 用于扩展 Webpack 的功能,执行更广泛的任务。它可以在 Webpack 运行的不同阶段执行各种任务,比如优化、压缩、代码分割、模块热替换等。
8.1 如何实现一个 Loader?
在 Webpack 中 Loader 是一个普通函数,该函数接收上一个 Loader 处理后的源码内容,并返回当前 Loader 处理后的源码内容。
创建 Loader:
// source表示上一个Loader处理后的文件源内容
module.exports = function (source) {
// 对源代码进行处理
const result = transform(source)
return result
}
function transform(source) {
// 实际的转换逻辑
// 可以使用正则表达式、字符串替换、AST解析等方式进行处理
return source.toUpperCase()
}注册 Loader:
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
{
test: /\.js$/, // 匹配需要使用该Loader的文件
use: 'path/to/custom-loader.js', // 指定Loader的路径
exclude: /node_modules/, // 可选,排除的文件夹
},
],
},
// ...
}8.2 如何实现一个 Plugin?
在 Webpack 中,Plugin 是一个 JavaScript 命名函数或 JavaScript 类,Plugin 需要提供 apply()函数,该方法在 Webpack 构建过程中被调用,允许在不同的生命周期钩子上执行自定义任务。
创建 Plugin:
// 自定义Plugin
class CustomPlugin {
// options表示插件的配置参数,可选
constructor(options) {
this.options = options || {}
}
// Plugin需要提供一个apply(),该方法在 Webpack 构建过程中被调用
apply(compiler) {
// 在compiler对象上注册Webpack生命周期钩子
compiler.hooks.emit.tapAsync('CustomPlugin', (compilation, callback) => {
// 执行自定义处理逻辑...
// 调用回调函数通知Webpack继续构建
callback()
})
}
}
module.exports = CustomPlugin注册 Plugin:
// webpack.config.js
// 导入自定义插件
const CustomPlugin = require('./path/to/CustomPlugin')
module.exports = {
// ...
plugins: [
new CustomPlugin({
/* 插件配置参数 */
}),
],
}9.Webpack 热更新(HMR)是什么?
Webpack 的热更新(Hot Module Replacement,简称 HMR)是一种能够在开发过程中实时更新应用程序的技术。它允许在不刷新整个页面的情况下,替换、添加或删除模块,从而实现快速的开发和调试体验。Webpack HMR 的实现原理涉及以下几个关键步骤:
- 模块热替换处理器(HMR runtime):在应用程序启动时,Webpack 将注入一个小型的运行时代码到 bundle 中,这个代码被称为模块热替换处理器(HMR runtime)。
- 监视文件变化:Webpack 会监视所有已加载模块的文件变化。当任何一个文件发生变化时,Webpack 将会触发一个构建事件。
- 模块更新检测:在开发过程中,当开发者修改了一个或多个模块,并保存这些修改时,Webpack 检测到文件的变化,并使用 HMR runtime 来通知应用程序的运行时环境。
- 热更新模块:应用程序的运行时环境(通常是浏览器)接收到更新通知后,通过热更新模块来决定如何处理这些变化。例如,它可能会尝试用新模块替换旧模块,或者在不刷新页面的情况下添加、删除或修改模块。
- 应用更新:最终,新的模块会被应用到运行中的应用程序中,以实现实时更新效果。这种方式通常比传统的完全刷新页面的方式更快速和流畅。
10.Webpack Proxy 工作原理?
Webpack 的 Proxy 功能允许开发者在开发过程中将某些 HTTP 请求代理到指定的目标服务器,通常用于解决开发环境下的跨域请求问题或者将请求转发到后端服务。Webpack 的 Proxy 工作原理可以简述为以下几个步骤:
- 配置代理规则:在 webpack 的配置文件(通常是 webpack.config.js)或者开发服务器的配置中,通过设置 devServer.proxy 来定义需要代理的规则。这些规则通常包括请求的路径和目标服务器的地址。
- 监听请求:当开发服务器(如 webpack-dev-server)启动时,它会监听来自客户端的所有 HTTP 请求。
- 匹配请求:对每个请求,开发服务器会检查是否有与请求路径匹配的代理规则。
- 代理转发:如果找到匹配的代理规则,开发服务器会将该请求转发到规定的目标服务器。如果没有匹配的代理规则,开发服务器将继续处理请求,通常是提供静态文件或者其他开发环境的服务。
- 返回响应:目标服务器收到请求后,利用 WebSocket 技术来与客户端保持持久连接,处理并生成相应的响应。开发服务器将目标服务器的响应返回给客户端,客户端继续进行后续的处理。
11.Tree Shaking 的原理?
Tree Shaking 是一个术语,用于描述在打包过程中移除 JavaScript 中未使用的代码(dead code elimination),以减少最终打包文件的体积。它特别针对 ES6 模块(即 import 和 export 语法),因为 ES6 模块具有静态特性,使得工具可以在编译时进行静态分析,识别和删除未使用的代码块。Webpack Tree Shaking 的原理如下:
- 静态分析阶段:Webpack 在编译过程中会对模块进行静态分析。静态分析是指在不执行代码的情况下分析代码结构,主要通过 AST(抽象语法树)分析来实现。
- 标记未引用代码:对于 ES6 模块系统中的每个模块,Webpack 标记所有导出的成员(函数、变量等)。然后,它分析代码入口(entry)以及与其相关联的依赖模块,找出哪些导出成员被引用了。
- 删除未引用代码:根据静态分析的结果,Webpack 可以安全地移除没有被引用的代码。这意味着未被任何导入模块直接或间接引用的代码将会被删除,从而减少打包后的文件大小。
12.Webpack hash、chunkhash 和 contenthash 的区别?
在 Webpack 中,hash、chunkhash 和 contenthash 是三种不同的哈希值,用于在生成打包文件时实现缓存控制和版本管理:
- hash:hash 是与整个编译过程相关的哈希值。每次编译时,无论项目中的哪些文件发生变化,hash 都会改变。通常用于生成与整个项目构建相关的文件名,例如 bundle.[hash].js。使用 hash 每次构建都会生成新的文件名,即使是很小的改动,所有包含 hash 的文件名都会改变,导致浏览器缓存失效,从而增加不必要的下载量。
- chunkhash:chunkhash 是基于 Webpack 中的每个 Chunk(代码块)生成的哈希值。只有当某个 Chunk 中的内容发生变化时,其对应的 chunkhash 才会改变。通常用于生成与具体代码块相关的文件名,例如分离的代码块和入口文件(分包情况下使用),例如 bundle.[chunkhash].js。相比较 hash,chunkhash 更加精细,只有修改的代码块的文件名会改变,未修改的代码块文件名保持不变,从而有效利用缓存。
- contenthash:contenthash 是基于文件内容生成的哈希值。只有当文件的内容发生变化时,contenthash 才会改变。主要用于生成与静态资源(如 CSS 文件和图像)相关的文件名,例如 styles.[contenthash].css。contenthash 是最精细的缓存控制方式,只有文件内容发生变化时,文件名才会改变,确保浏览器最大限度地利用缓存提升性能。
13.Webpack Module Federation 是什么?
Webpack Module Federation(模块联邦) 是 Webpack 5 引入的一项强大功能,旨在实现微前端架构,使得不同应用可以共享代码和模块。它允许在运行时动态加载和共享模块,从而实现多个独立构建的应用之间的模块共享。Module Federation 定义了 Host 和 Remote 两个主要角色,Host 表示需要加载和使用其他应用模块的应用(也叫本地应用),Remote 表示被其他应用加载和使用的应用(也叫远程应用)。Webpack Module Federation 示例如下:
// Remote应用webpack.config.js,向外部暴露了Button组件
const ModuleFederationPlugin = require('webpack/lib/container/ModuleFederationPlugin')
module.exports = {
// ...其他配置
plugins: [
new ModuleFederationPlugin({
// 应用名称
name: 'app1',
/**
* remoteEntry.js 是 Webpack Module Federation 中远程容器(Remote Container)的输出文件。
* 它是一个由 Webpack 打包生成的 JavaScript 文件,
* 主要作用是描述远程应用所暴露的模块和如何加载这些模块。
*/
filename: 'remoteEntry.js',
exposes: {
'./Button': './src/Button',
},
}),
],
}
// Host应用webpack.config.js,通过remotes配置引用了Remote应用
const ModuleFederationPlugin = require('webpack/lib/container/ModuleFederationPlugin')
module.exports = {
// ...其他配置
plugins: [
new ModuleFederationPlugin({
name: 'app2',
remotes: {
app1: 'app1@http://localhost:3001/remoteEntry.js',
},
}),
],
}
// 在Host应用使用Remote应用暴露的Button组件
import React from 'react'
import ReactDOM from 'react-dom'
const Button = React.lazy(() => import('app1/Button'))
const App = () => (
<React.Suspense fallback="Loading...">
<Button />
</React.Suspense>
)
ReactDOM.render(<App />, document.getElementById('root'))Webpack 提供的 ModuleFederationPlugin 插件是实现模块联邦的核心。它负责在编译阶段生成模块清单、配置暴露和引用的模块,并在运行时动态加载模块:
- 模块清单生成:在编译阶段,Module Federation 插件会为每个应用生成一个模块清单(manifest),该清单记录了应用中暴露的模块及其依赖关系。这些清单文件通常以 remoteEntry.js 命名。
- 模块暴露:通过 exposes 配置,应用可以指定哪些模块可以被其他应用使用。Webpack 会为这些模块生成对应的打包文件,并在清单中记录它们的路径和依赖。
- 远程模块引用:通过 remotes 配置,应用可以指定从哪些远程地址加载模块。远程模块地址通常包括远程应用的名称和其清单文件的 URL。例如
http://localhost:3001/remoteEntry.js。 - 动态模块加载:当应用在运行时需要加载一个远程模块时,Webpack 会先加载对应的清单文件(如 remoteEntry.js),然后根据清单信息动态加载需要的模块文件。
- 模块共享:通过 shared 配置,应用可以指定共享的模块和依赖。Webpack 会确保在同一版本范围内只加载一次共享模块,以避免重复加载和版本冲突。
14.Webpack 的优化策略有哪些?
- 使用 speed-measure-webpack-plugin 或 webpack-bundle-analyzer 插件进行量化分析和监控 bundle。首先通过 speed-measure-webpack-plugin 插件量化分析各个 plugin 和 loader 打包时所花费的时间,通过量化指标可以看出优化前与优化后的对比。webpack-bundle-analyzer 是一个用于监控 bundle 体积插件,可以通过该插件监控 bundle 打包体积,根据分析结果进一步优化。
- 通过 exclude 或 include 配置来确保转译尽可能少的文件。通过 exclude 排除无需打包的目录(例如 exclude:/\node_modules/排除 node_modules 目录),exclude 的优先级高于 include(优先匹配 exclude)。include 用于包含指定目录下的模块进行打包,一般会将 include 配置为 src,建议使用 include,避免使用 exclude,指定 include 大分部情况比指定 exclude 构建效果要好。
- 使用 cache-loader。对于一些性能开销比较大的 loader 之前添加 cache-loader,将结果缓存到磁盘中,能大幅度提升性能,默认缓存保存在 node_modules/.cache/cache-loader 目录下。
- 使用 happypack 插件进行多线程打包。happypack 是一个通过多线程来提升 webpack 打包速度的工具。
- 使用 thread-loader 进行多线程打包。除了使用 Happypack 提升打包速度,也可以使用 thread-loader,把 thread-loader 放置在其他 loader 之前,那么放置在这个 loader 之后的 loader 就会在一个单独的 worker 池中运行。
- 使用 terser-webpack-plugin 和 mini-css-extract-plugin 插件分别对 JS 和 CSS 资源压缩。资源压缩包括 JS 与 CSS 文件压缩,terser-webpack-plugin 是一个用于压缩 JS 资源的插件。压缩 CSS 前首先使用 mini-css-extract-plugin 插件将 CSS 提取出来,然后使用 optimize-css-assets-webpack-plugin 进行压缩。
- 使用 noParse 标识模块不进行转化与解析。如果一些第三方模块没有 AMD/CommonJS 规范版本,这对打包影响还是挺大的,我们可以使用 noParse 来标识这个模块,这个 webpack 会引入这些模块,但是不进行转化和解析,从而提升 webpack 的构建性能,例如 jquery、lodash。noParse 属性的值可是一个正则表达式或一个 function。
- 使用 IgnorePlugin 忽略第三方依赖。IgnorePlugin 是 webpack 的内置插件,作用是忽略第三方依赖指定目录。例如: moment (2.24.0 版本) 会将所有本地化内容和核心功能一起打包,可以使用 IgnorePlugin 在打包时忽略本地化内容。
- 使用 externals 从 bundle 排除依赖项。xternals(外部扩展)配置选项提供了「从输出的 bundle 中排除依赖」的方法。防止将某些 import 的包(package)打包到 bundle 中,而是在运行时(runtime)再去从外部获取这些扩展依赖(external dependencies)。
- 使用 DllPlugin 或 DLLReferencePlugin 插件拆分 bundle。如果所有的 js 文件都打包成一个 JS 文件,这会导致最终生成的 js 文件体积很大,这个时候就要考虑拆分 bundle 了。DllPlugin 和 DLLReferencePlugin 可以实现拆分 bundles,并且可以大幅度提升构建速度,DllPlugin 和 DLLReferencePlugin 都是 webpack 的内置模块。
- 抽离公共代码。optimization.SplitChunks(简称 SplitChunks)是 webpack4 为了改进 CommonsChunk-Plugin 而重新设计和实现的代码分片特性。webpack4 之前自带 CommonsChunk-Plugin 插件用于处理代码分片,webpack4 后使用 SplitChunks,SplitChunks 相比 CommonsChunk-Plugin 功能更加强大,操作更加简单。
- 尽量使用 ESModule。ES6 Module 依赖关系的构建是在代码编译时而非运行时,基于这一特性 webpack 提供了 tree shaking(摇树)功能,它可以在打包过程中检测工程中未使用过的模块,这部分代码将不会被执行,因此被称为"死代码"。webpack 会对这部分代码进行标记,并在资源压缩时将它们从最终的 bundle 中去掉。
- 使用 swc-loader 或 esbuild-loader 提升打包速度。JS 是一门动态采用单线程模型的脚本语言,性能成为了 JS 的瓶颈,为了追求更极致的性能前端工程化建设基本朝 rust 和 go 语言方向偏移,rust 和 go 能大幅度提升程序执行效率。swc 就是基于 rust 开发的一款对标 babel 的模块打包器,esbuild 是基于 go 语言实现的一款打包器,它们基于更底层的静态语言,打包构建的速度非常快。
- 升级 Webpack5。Webpack5 通过引入新的持久性缓存机制,加快了构建速度。持久性缓存允许 Webpack 缓存每个模块的内容和 ID,并将它们存储在磁盘上,以便下次重新构建时能够快速加载。其次 Webpack5 默认使用 ESModule,并改进其 Tree Shaking 算法来提高性能,改进后的算法可以更好的识别"死代码",可以从最终打包的代码中删除,从而减小代码体积。
15.什么是 Vite?Vite 的打包原理?
Vite 是一种新型前端构建工具,能够显著提升前端开发体验,它利用浏览器了 ESM 特性导入组织代码,在服务器端按需编译返回,完全跳过了打包过程。Vite 具有如下优点:
- 快速的冷启动: No Bundle + esbuild 预构建。
- 即时的模块热更新: 基于 ESM 的 HMR,同时利用浏览器缓存策略提升速度。
- 真正的按需加载: 利用浏览器 ESM 支持,实现真正的按需加载。
在 Vite 出来之前,传统的打包工具如 Webpack 是先根据入口(entry)解析依赖组织成一个模块依赖图、打包构建再启动开发服务器,Dev Server 必须等待所有模块构建完成,当修改 bundle 模块中的一个子模块,整个 bundle 文件都会重新打包然后输出。在项目应用越大情况下启动时间也会越长。
Vite 的核心原理是利用 ES6 的 import,当在客户端(浏览器)解析到 import 语句时就会发送一个 HTTP 请求去加载对应模块。Vite 启动一个 koa 服务器拦截这些请求,并在服务端进行相应的处理,将项目中使用的文件通过简单的分解与整合,然后再以 ESM 格式返回给客户端。由于 Vite 整个过程中没有对文件进行打包编译(No Bundle),做到了真正的按需加载,所以其运行速度比原始的 webpack 开发编译速度快出许多。其次 Vite 在开发环境基于 esbuild(Esbuild 是一个基于 Golang 语言实现打打包器,借助编译型语言和 Golang 协程等优点,对比其他打包工具有几十甚至几百倍的性能提升)进行依赖预编译优化,不仅提供 CommonJS 模块转 ESM(由于 Vite 只支持 ESM 模块,因此在预构建阶段会使用 esbuild 将 CommonJS 转为 ESM,并缓存在 node_modules/.vite目录),而且可以根据内部模块的 ESM 依赖关系转换为单个模块,减少模块和请求数量,从而提高页面加载性能。由于 Vite 在开发环境使用 esbuild 进行预构建,生产环境使用 rollup 作为打包工具,因此可能会造成生产环境与开发环境效果不一致的问题,目前 Vite 团队打算使用 rolldown 替换 esbuild 和 rollup 作为其底层打包工具,来解决生产环境与开发环境打包一致性问题。
16.为什么Vite性能比Webpack好?
Webpack 采用**打包器(Bundler)**架构,其核心工作流程可以概括为:
- 依赖收集:从入口文件出发,递归分析所有依赖。
- 构建依赖图:形成完整的模块依赖关系图。
- 打包编译:将所有模块打包成一个或多个 bundle。
- 启动开发服务器:提供服务并监听文件变化。
Webpack采用全量打包方式,只要依赖文件发生变化,就会重新构建整个依赖图,当项目规模越大,打包时间就会越长。而Vite 的核心创新在于开发环境完全摒弃了打包概念,直接利用现代浏览器对 ESM 的原生支持,采用按需打包方式。当用户请求到某个模块时,Vite会拦截该请求并按需编译对应的模块,这样可以避免必要的编译工作,极大的提升了打包效率。
其次,Vite 在首次启动时会进行依赖预构建:
- 扫描 package.json 中的依赖。
- 使用 esbuild 将 CommonJS/UMD 依赖转换为 ESM。esbuild是一个基于go语言实现的打包器,比传统工具快 10-100 倍。
- 合并多个小文件以减少请求数量。
- 缓存构建结果提高后续启动速度。
得益于 Vite 基于 ESM 的按需打包和依赖预构建机制,可以直接在浏览器中运行 ESM 模块,无需打包。这一特性使得 Vite 在开发环境中具有非常快的冷启动速度,几乎可以瞬间启动。
17.什么是 Vite Plugin?如何自定义一个 Plugin?
使用 Vite 插件可以扩展 Vite 能力,通过暴露一些构建打包过程的一些时机配合工具函数,让用户可以自定义地写一些配置代码,执行在打包过程中。比如解析用户自定义的文件输入,在打包代码前转译代码或者查找。在开发中,Vite 开发服务器会创建一个插件容器来调用 Rollup 构建钩子,Vite 的钩子包含通用钩子和 Vite 独有钩子:
- 在服务器启动时被调用的钩子(通用钩子):
- options:获取、操纵 Rollup 选项。
- buildStart:开始创建时调用。
- 在每个传入模块请求时被调用的钩子(通用钩子):
- resolveId:用于解析模块路径。当 Vite 遇到一个 import 语句时,它会调用 resolveId 钩子来确定模块的绝对路径。
- load:用于加载模块内容。在模块路径解析后,Vite 会调用 load 钩子来读取模块的内容。
- transform:用于转换模块内容。在模块内容加载后,Vite 会调用 transform 钩子来对模块内容进行转换,比如编译 TypeScript、处理 JSX 等。这个钩子函数接受两个参数:模块的内容 code 和模块的路径 id。返回值应该是一个对象,包含转换后的 code 和可选的 map(源码映射)。如果返回 null 或 undefined,则表示未处理,Vite 会使用默认的转换逻辑继续处理。
- 在服务器关闭时被调用的钩子(通用钩子):
- buildEnd:。
- closeBundle:。
- config:在解析 Vite 配置前调用。钩子接收原始用户配置(命令行选项指定的会与配置文件合并)和一个描述配置环境的变量,包含正在使用的 mode 和 command。
- configResolved:在解析 Vite 配置后调用。使用这个钩子读取和存储最终解析的配置。
- configureServer:用于配置开发服务器的钩子。最常见的用例是在内部 connect 应用程序中添加自定义中间件。
- configurePreviewServer:在其他中间件安装前被调用的。
- transformIndexHtml:转换 index.html 的专用钩子。钩子接收当前的 HTML 字符串和转换上下文。上下文在开发期间暴露 ViteDevServer 实例,在构建期间暴露 Rollup 输出的包。
- handleHotUpdate:执行自定义 HMR 更新处理。
Vite plugin 本质上是一个返回 plugin 对象(包含插件名称和 plugin 钩子函数等属性)的函数,自定义 plugin 如下:
import { type Plugin, createFilter, defineConfig } from 'vite'
/**
* 删除console.log语句 plugin,其核心使用正则匹配替换console.log,当源码内容体积很大时,
* 正则匹配替换可能存在性能问题,可以使用babel、swc等编译器实现删除console.log,同时
* babel、swc也支持更多特性(代码转换),灵活性和性能也会更好。
*/
export function removeConsoleLog() {
// 过滤器,用于筛选要处理的文件
const filter = createFilter(/\.(ts|vue)$/)
return {
// 插件name,vite推荐以 vite-plugin-作为前缀
name: 'vite-plugin-remove-consoleLog',
// 控制插件执行顺序,pre表示在Vite核心插件之前执行,post表示在用户插件和Vite 构建用的插件之后执行
enforce: 'post',
/**
* 转换模块内容钩子
* @param code 模块源码,字符串
* @param id 模块id(模块path),字符串
*/
transform(code, id) {
// 仅处理符合过滤器的文件
if (!filter(id)) {
return
}
// 使用正则表达式移除 console.log 语句
const cleanedCode = code.replace(/console\.log\([^)]*\);?/g, '')
return {
// 返回处理后的模块源码
code: cleanedCode,
// sourceMap(源码映射,通常用于调试)
map: null,
}
},
} as Plugin
}
// 使用 removeConsoleLog plugin
export default defineConfig({
// ...省略其他配置
plugins: [removeConsoleLog()],
})18.Vite 的优化策略有哪些?
- 查看模块依赖分析。分析依赖模块的大小占比,可以有针对性对某些模块进行体积优化。rollup-plugin-visualizer 是一个模块依赖分析插件,通过该插件可以对模块依赖进行构建分析。
# 安装
pnpm i rollup-plugin-visualizer -D- 分包策略。分包是一种将不常更新的文件进行单独打包的优化策略。vite 在打包时,会在 bundle 添加一个 hash 值,该 hash 与文件内容相关,当文件内容发生变化,hash 值也会发生变化,这样做能保证文件发生变化时浏览器能够请求到最新资源。对于不常变化的文件,可以借助分包机制将不常变化的文件进行单独打包,这种方式可以充分利用浏览器缓存提升加载效率(请求相同资源会命中浏览器缓存),例如将第三方包进行独立打包。在 vite 中分包依赖于 rollup 的 output.manualChunks,当该选项值为函数形式时,每个被解析的模块都会经过该函数处理。如果函数返回字符串,那么该模块及其所有依赖将被添加到以返回字符串命名的自定义 chunk 中。
import { defineConfig } from 'vite'
export default defineConfig({
build: {
minify: false,
// 在这里配置打包时的rollup配置
rollupOptions: {
manualChunks: (id) => {
if (id.includes('node_modules')) {
// 打包后生成一个vendor.xxxxx.js
return 'vendor'
}
},
},
},
})经过分包策略后,可能会导致打包后的体积过大,此时可以使用vite-plugin-compression2插件进行打包压缩。
pnpm install vite-plugin-compression2 -D- 开启 treeshaking。treeshaking 也被称为 "摇树优化"。简单来说,在保证代码运行结果不变的前提下,去除无用的代码,从而减少打包后产物的体积大小。但是使用 treeshaking 机制时,必须要保证使用 ESModule 模块化方式组织代码,因为 ESModule 使用静态分析,可以检测无使用的死代码。
- 开启 gzip 压缩。gzip 是一种使用非常普遍的压缩格式。使用 gzip 压缩可以大幅减小代码体积,提升网络性能(对于文本内容压缩效率更好)。
# 安装 vite gzip插件
pnpm i vite-plugin-compression -D- 开启 CDN 加速。内容分发网络(Content Delivery Network,简称 CDN)允许用户从最近的服务器请求资源,提升网络请求的响应速度。
# 安装Vite CDN加速插件
npm i vite-plugin-cdn-import -D- 使用图片压缩。当项目存在大量图片或大图片时,除了使用体积更小的图片格式外(例如 webp),此时还可以使用图片压缩。
# 安装图片压缩插件
pnpm i vite-plugin-imagemin -D19.前端性能指标有哪些?
前端性能指标是衡量网页或应用加载速度、渲染效率和用户体验的重要标准
加载性能指标:
- FCP(First Contentful Paint,即首次内容绘制):
- 定义:首次内容绘制是指浏览器渲染出第一个非空内容(如文本、图片、SVG 等)的时间点。
- 作用:评估网页加载速度,用户感知到的页面加载速度。
- LCP(Largest Contentful Paint,即最大内容绘制):
- 定义:最大内容绘制是指浏览器渲染出页面中最大的内容元素(如图片、视频等)的时间点。
- 作用:评估网页加载速度,用户感知到的页面加载速度。
- FP(First Paint,即首次绘制):
- 定义:首次绘制是指浏览器渲染出任何内容的时间点。
- 作用:评估网页加载速度,用户感知到的页面加载速度。
- TTFB(Time To First Byte,即首次字节响应时间):
- 定义:首次字节响应时间是指浏览器从发送请求到收到第一个字节响应的时间。
- 作用:评估服务器响应速度,用户感知到的页面加载速度。
- DOM Ready / Interactive:
- 定义:DOM Ready 是指 DOM 树解析完成,所有脚本执行完成的时间点。Interactive 是指用户可以与页面交互的时间点。
- 作用:评估网页加载速度,用户感知到的页面加载速度。
- OnLoad:
- 定义:OnLoad 是指页面所有资源(如图片、视频等)加载完成的时间点。
- 作用:评估网页加载速度,用户感知到的页面加载速度。
交互性能指标: FID(First Input Delay,即首次输入延迟):
- 定义:首次输入延迟是指用户首次与页面交互(如点击、滚动等)到浏览器响应的时间延迟。
- 作用:评估用户与页面交互的响应速度,用户感知到的页面交互效率。 TTI(Time To Interactive,即可交互时间):
- 定义:可交互时间是指用户可以与页面交互的时间点,即 DOM Ready 或 Interactive 时间点。
- 作用:评估用户与页面交互的响应速度,用户感知到的页面交互效率。 TBT(Total Blocking Time,即总阻塞时间):
- 定义:总阻塞时间是指在用户首次与页面交互(如点击、滚动等)到 TTI 时间点之间,所有长任务(执行时间超过 50ms)的阻塞时间总和。
- 作用:评估用户与页面交互的响应速度,用户感知到的页面交互效率。 Event Latency(事件延迟):
- 定义:事件延迟是指用户触发事件(如点击、滚动等)到浏览器响应事件的时间延迟。
- 作用:评估用户与页面交互的响应速度,用户感知到的页面交互效率。
渲染性能指标(Rendering / Visual): FPS (Frames Per Second):
- 定义:每秒渲染的帧数,衡量页面的渲染效率。
- 作用:评估页面的渲染效率,用户感知到的页面渲染速度。 CLS (Cumulative Layout Shift):
- 定义:累计布局偏移是指在页面加载过程中,所有布局偏移(如元素位置变化)的总和。
- 作用:评估页面的渲染效率,用户感知到的页面渲染速度。 JS 执行时间:
- 定义:JS 执行时间是指浏览器执行 JavaScript 代码的时间。
- 作用:评估页面的渲染效率,用户感知到的页面渲染速度。 Reflow / Repaint:
- 定义:Reflow 是指元素位置或尺寸变化导致的重新布局过程。Repaint 是指元素外观变化导致的重新绘制过程。
- 作用:评估页面的渲染效率,用户感知到的页面渲染速度。